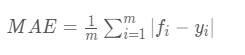
建模的评估一般可以分为回归、分类和聚类的评估,本文主要介绍回归和分类的模型评估:
主要有以下方法:
指标 描述 metrics方法
Mean Absolute Error(MAE) 平均绝对误差 from sklearn.metrics import mean_absolute_error
Mean Square Error(MSE) 平均方差 from sklearn.metrics import mean_squared_error
R-Squared R平方值 from sklearn.metrics import r2_score
#sklearn的调用
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
mean_absolute_error(y_test,y_predict)
mean_squared_error(y_test,y_predict)
r2_score(y_test,y_predict)
平均绝对误差就是指预测值与真实值之间平均相差多大 :
平均绝对误差能更好地反映预测值误差的实际情况.
观测值与真值偏差的平方和与观测次数的比值:
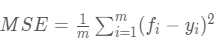
这也是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精度。
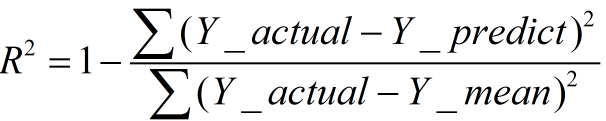
数学理解: 分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响
其实“决定系数”是通过数据的变化来表征一个拟合的好坏。 理论上取值范围(-∞,1], 正常取值范围为[0 1] ------实际操作中通常会选择拟合较好的曲线计算R²,因此很少出现-∞